Em ambientes de larga escala, os problemas de cache distribuído são mais evidentes e problemáticos. Imagine, por exemplo, um sistema distribuído que receba 10.000 RPS requests per second. Para se ter ideia da dimensão:
- 1 minuto: 600.000 requisições
- 1 hora: 36.000.000 requisições
A Netflix, por exemplo, já publicou em seu blog de engenharia que suas APIs recebem cerca de 20.000 rps em horários de pico.
The Netflix API receives around 20,000 requests per second at peak traffic.
Imagine um cenário ainda mais caótico, em produção, onde o banco de dados já apresenta uma leve degradação devido ao uso sistêmico — com queries simples levando entre 50–100ms para serem completadas. Quando multiplicamos isso por um alto volume de requisições, o problema se intensifica rapidamente.
Milhares de threads passam a atingir o banco simultaneamente → o pool de conexões é esgotado → começam a ocorrer timeouts em cascata → e, por fim, o banco colapsa sob a própria carga gerada pelo cache stampede.
Esse volume ajuda a ilustrar o tamanho do impacto que um problema como cache stampede pode causar. Além de afetar a performance da aplicação, ele pode gerar aumento de custos de infraestrutura, sobrecarga na base de dados e piora perceptível na experiência do usuário.
Exemplos que já custaram tempo e dinheiro das big techs
Early today Facebook was down or unreachable for many of you for approximately 2.5 hours. This is the worst outage we’ve had in over four years
Facebook, 2010
At 2:47 AM on Black Friday 2019, Shopify’s product recommendation cache expired. Within 3 seconds, 47,000 concurrent requests slammed their primary database
Shopify, 2019
O Problema
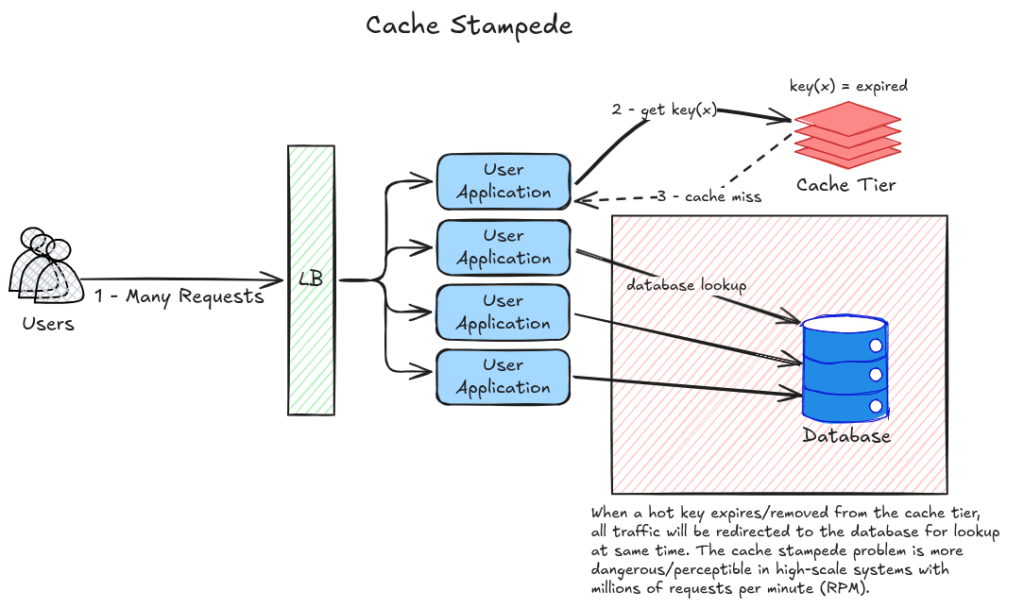
Cache stampede, também conhecido como thundering herd, é um problema que acontece quando uma hot key do cache expira ou é invalidada e, ao mesmo tempo, milhares de requisições concorrentes tentam acessar essa mesma chave.
Como o dado não está mais disponível na camada de cache, todas essas requisições acabam sendo redirecionadas para a fonte principal de dados — geralmente banco de dados ou API externa.
Esse comportamento gera um pico abrupto de carga justamente na camada mais cara e mais lenta do sistema.
Na prática, os principais impactos são:
- aumento repentino da latência;
- saturação do pool de conexões do banco;
- degradação de outras operações críticas;
- timeouts em cascata;
- aumento de custo com auto scaling.
Em soluções gerenciadas, como AWS Aurora, isso pode inclusive disparar escalonamentos automáticos desnecessários.
Soluções
Existem algumas soluções disponíveis no mercado para mitigar o problema de cache stampede. Porém, não existe bala de prata: toda solução em engenharia de software possui trade-offs. O ponto principal é escolher a abordagem mais adequada para o contexto da aplicação.
External re-computation
Neste caso específico, separamos a atualização da leitura. Podemos ter um agente externo — como um sistema à parte da aplicação — responsável por consultar a base de dados e atualizar o cache diretamente.
Outra alternativa é utilizar um job dentro da própria aplicação, executado em intervalos de tempo, para verificar quais chaves estão próximas da expiração e regenerar os dados antes que expirem.
Essa abordagem reduz a chance de bursts repentinos no momento da leitura, já que o dado tende a estar previamente aquecido no cache.
Pontos positivos:
- Reduz a probabilidade de cache stampede no momento da requisição;
- Diminui a pressão sobre a base de dados em picos de acesso;
- Melhora a previsibilidade do comportamento do sistema;
- Pode manter hot keys sempre aquecidas.
Pontos negativos:
- Aumenta a complexidade operacional do sistema;
- Depende da disponibilidade do agente externo ou job agendado;
- Se o processo de atualização falhar, o stampede ainda pode acontecer;
- Pode gerar custo computacional desnecessário ao atualizar chaves pouco acessadas ou nunca utilizadas;
- Dificulta o gerenciamento quando muitas chaves expiram próximas umas das outras.
Ponto importante: a estratégia de cache-aside perde parte do sentido caso você opte por external re-computation, já que, no cache-aside, a regeneração acontece naturalmente sob demanda quando o dado expira.
Nesse cenário, faz mais sentido utilizar uma abordagem como read-through + external re-computation (refresh ahead / write-through), pois o fluxo de atualização passa a ser mais previsível e controlado.
Lock (Mutex)
O lock, por definição, impede que requisições concorrentes acessem o mesmo recurso ao mesmo tempo.
Na prática, entre milhares de requisições que chegam simultaneamente ao serviço, apenas a primeira que conseguir adquirir o lock será responsável por regenerar o dado em cache. Após concluir a atualização, ela libera o lock para que as demais requisições reutilizem o valor já regenerado.
Dessa forma, mitigamos o problema de cache stampede, evitando que todas as requisições sejam redirecionadas simultaneamente para a base de dados.
Pontos positivos:
- Evita avalanche de consultas concorrentes na base de dados;
- Garante que apenas uma thread regenere o cache;
- Mantém maior consistência dos dados;
- É simples de implementar em cenários locais.
Pontos negativos:
- Pode degradar a performance em cenários de alta contenção;
- Aumenta a latência enquanto a thread responsável pela recomputação não libera o lock;
- As demais threads ficam bloqueadas aguardando;
- Pode gerar filas e gargalos em horários de pico;
- Não funciona bem em cenários com múltiplas instâncias, pois o lock é apenas local.
Ponto importante: é uma abordagem indicada para ambientes que exigem alta consistência, pois, mesmo em cenários de falha, o dado servido ao cliente tende a refletir o estado mais atualizado possível.
Distributed Lock
Mesma coisa que o mutex, exceto pelo fato de externalizamos o controle de concorrência para um sistema compartilhado, como Redis, ZooKeeper e Shedlock permitindo que múltiplas instâncias da aplicação respeitem o mesmo mecanismo de sincronização.
Na prática, quando uma hot key expira e várias requisições chegam ao mesmo tempo, apenas a primeira que adquirir o lock será responsável por buscar o dado na fonte principal e atualizar o cache. As demais aguardam ou reutilizam o valor atualizado. Dessa forma, evitamos recomputações duplicadas e reduzimos o risco de cache stampede em ambientes distribuídos.
Pontos positivos:
- Evita múltiplas recomputações simultâneas;
- Reduz carga na base de dados;
- Melhora a consistência em múltiplas instâncias.
Pontos negativos:
- Adiciona dependência de um sistema externo;
- Pode aumentar latência em cenários de alta contenção.
Ponto importante: é uma abordagem recomendada para aplicações distribuídas em que consistência é prioridade.
TTL Jitter (Staggered)
TTL jitter mitiga o problema de stampede, mas não o resolve completamente.
Basicamente, essa técnica calcula o TTL acrescentando um delta de tempo ao valor original, distribuindo melhor os tempos de expiração ao invés de usar um valor fixo.
É importante destacar que existem diferentes formas de aplicar TTL jitter, como:
- Exponencial: distribui melhor os tempos de expiração em cenários de maior escala.
- Fixo: adiciona ou subtrai um valor pré-definido ao TTL base;
- Aleatório: aplica uma variação randômica dentro de uma faixa;
Contudo, estamos apenas mitigando, não evitando o stampede. O cálculo pode, aleatoriamente, gerar um TTL maior para um dado em cache que quase nunca é requisitado, enquanto uma hot key continua com TTL baixo.
Ponto importante: é uma solução simples de implementar e geralmente é utilizada em conjunto com outras técnicas para aumentar sua efetividade.
Probabilistic Early Expiration
Nesta estratégia, o dado cache é regenerado antes da expiração de forma probabilística, reduzindo o risco de cache stampede sem depender de locks distribuídos. Tornando toda requisição ao serviço um potencial candidato à regeneração antecipada do cache.
O funcionamento é simples: sempre que uma requisição acessa um dado em cache, ela calcula um tempo aleatório de antecipação gap e verifica se já está próxima o suficiente da expiração para assumir a recomputação do valor.
A distribuição exponencial é uma boa escolha para definir esse intervalo de antecipação:
Na prática, o gap é calculado por:
Onde:
Δ= tempo da última recomputação do valor em cacheβ= fator de ajuste da agressividade da estratégiaU= valor aleatório entre0e1
Com o gap calculado, a requisição verifica:
Se a condição for verdadeira, ela assume a responsabilidade de regenerar o cache antes da expiração real. Caso contrário, o valor atual é retornado normalmente.
Ponto importante: essa abordagem distribui melhor as recomputações ao longo do tempo, reduzindo a chance de expirações simultâneas e sobrecarga na base de dados. Por trabalhar com uma janela de desatualização temporária, é uma estratégia mais indicada para fluxos que toleram consistência eventual. Uma má parametrização pode causar recomputações desnecessárias ou pouca antecipação.
Stale While Revalidate
Nesta abordagem, quando uma requisição é feita e a aplicação identifica que o dado em cache está expirado ou próximo da expiração, em vez de bloquear a resposta e consultar a base de dados naquele momento, ela retorna imediatamente o valor antigo para o consumidor. Paralelamente, um processo assíncrono é iniciado para buscar a versão atualizada na fonte principal e atualizar o cache para as próximas requisições.
Dessa forma, evitamos que o usuário espere pela recomputação ou pela consulta à base de dados no momento da requisição.
Pontos positivos:
- Alta disponibilidade;
- Baixa latência;
- Melhor experiência para o usuário em tempo de resposta;
- Reduz pressão imediata na base de dados.
Pontos negativos:
- Possibilidade de servir dados desatualizados;
- Exige tolerância à consistência eventual;
- Pode não ser adequado para dados críticos ou sensíveis.
Ponto importante: é uma estratégia recomendada para ambientes em que a consistência eventual é aceitável.
Implementação
Quase todas as implementações foram realizadas, com exceção do External Re-computation, por motivos de preguiça 😄.
As implementações foram feitas em classes separadas, utilizando o design pattern Strategy, com foco em legibilidade, testabilidade e facilidade de evolução. Quase todas as soluções foram validadas por meio de testes de carga utilizando k6; os resultados serão apresentados na seção de testes e métricas.
Ponto importante: alguns trechos de código foram omitidos para evitar verbosidade excessiva (Java) 😄
Lock (Mutex)
A implementação é simples e consiste em controlar a aquisição e liberação do lock local utilizando ReentrantLock. Em caso de cache miss, apenas uma thread executa a busca na base de dados, enquanto as demais aguardam, evitando race conditions e recomputações duplicadas.
@Component("MUTEX")
public class MutexStrategy implements StampedePreventionService {
...
private final ReentrantLock lock = new ReentrantLock();
@Override
public PreventionResult retrieve(String key, Supplier<Object> loader, Tags tags) {
var cached = cacheService.get(key, Object.class);
if (cached != null) {
meterRegistry.counter("cache.hit", tags).increment();
return new PreventionResult(cached, true);
}
lock.lock();
meterRegistry.counter("lock.aquired", tags).increment();
try {
cached = cacheService.get(key, Object.class);
if (cached != null) {
meterRegistry.counter("cache.hit", tags).increment();
return new PreventionResult(cached, true);
}
var value = loader.get();
cacheService.save(key, value);
meterRegistry.counter("cache.miss", tags).increment();
return new PreventionResult(value, false);
} finally {
meterRegistry.counter("lock.released", tags).increment();
lock.unlock();
}
}
}Distributed Lock (RLock)
A implementação é semelhante ao mutex, com a diferença de que o lock é externalizado para um sistema separado, como o Redis. Foi utilizada a biblioteca Redisson. Essa abordagem permite coordenar a concorrência entre múltiplas instâncias da aplicação, garantindo que apenas uma delas execute a recomputação do dado em caso de cache miss. A biblioteca abstrai a complexidade do lock distribuído, oferecendo mecanismos como reentrância e controle de expiração.
@Component("DLOCK")
public class DistributedLockStrategy implements StampedePreventionService {
private static final String LOCK_SUFFIX = ":lock";
private final RedissonClient redissonClient;
...
@Override
public PreventionResult retrieve(String key, Supplier<Object> loader, Tags tags) {
var cached = cacheService.get(key, CacheEntry.class);
if (cached != null) {
meterRegistry.counter("cache.hit", tags).increment();
return new PreventionResult(cached.value(), true);
}
RLock lock = redissonClient.getLock(key + LOCK_SUFFIX);
lock.lock();
meterRegistry.counter("lock.aquired", tags).increment();
try {
// double-check: lock-holder may have already populated cache
cached = cacheService.get(key, CacheEntry.class);
if (cached != null) {
meterRegistry.counter("cache.hit", tags).increment();
return new PreventionResult(cached.value(), true);
}
var value = loader.get();
cacheService.save(key, CacheEntry.of(value));
meterRegistry.counter("cache.miss", tags).increment();
return new PreventionResult(value, false);
} finally {
meterRegistry.counter("lock.released", tags).increment();
lock.unlock();
}
}
...
}TTL Jitter
A estratégia de jitter utilizada foi a aleatória. Sempre que o cache é repopulado, um valor aleatório é adicionado ao TTL base, dentro de um intervalo definido por maxJitterSeconds, distribuindo melhor os tempos de expiração das chaves.
@Component("JITTER")
public class JitterStrategy implements StampedePreventionService {
private final Random random = new Random();
@Value("${app.cache.base-ttl-minutes}")
private long baseTtlMinutes;
@Value("${app.jitter.max-seconds}")
private int maxJitterSeconds;
...
@Override
public PreventionResult retrieve(String key, Supplier<Object> loader, Tags tags) {
var cached = cacheService.get(key, CacheEntry.class);
if (cached != null) {
meterRegistry.counter("cache.hit", tags).increment();
return new PreventionResult(cached.value(), true);
}
var value = loader.get();
//Random TTL Jitter strategy
Duration ttl = Duration.ofMinutes(baseTtlMinutes)
.plusSeconds(random.nextInt(maxJitterSeconds));
cacheService.save(key, CacheEntry.of(value), ttl);
meterRegistry.counter("cache.miss", tags).increment();
return new PreventionResult(value, false);
}
...
}Probabilistic Early Expiration
Para implementar essa estratégia, é necessário armazenar alguns metadados junto com o dado em cache: a expiração absoluta (expiryMs) e o tempo da última recomputação do dado (deltaMs). Com essas informações em mãos, conseguimos calcular o gap de acordo com a fórmula descrita anteriormente.
@Component("PEE")
public class ProbabilisticEarlyExpirationStrategy implements StampedePreventionService {
private static final double BETA = 1.0;
@Value("${app.cache.base-ttl-minutes}")
private long baseTtlMinutes;
...
@Override
public PreventionResult retrieve(String key, Supplier<Object> loader, Tags tags) {
var cached = cacheService.get(key, CacheEntry.class);
if (cached != null) {
if (!shouldRecompute(cached.deltaMs(), cached.expiryMs())) {
meterRegistry.counter("cache.hit", tags).increment();
return new PreventionResult(cached.value(), true);
}
meterRegistry.counter("cache.early.recompute", tags).increment();
}
long start = System.currentTimeMillis();
var value = loader.get();
long deltaElapsed = System.currentTimeMillis() - start;
Duration ttl = Duration.ofMinutes(baseTtlMinutes);
//Exact expiration moment
long expiration = System.currentTimeMillis() + ttl.toMillis();
cacheService.save(key, CacheEntry.forProbabilistic(value, deltaElapsed, expiration), ttl);
meterRegistry.counter("cache.miss", tags).increment();
return new PreventionResult(value, false);
}
/**
* Recompute early if now + (-deltaElapsed) * beta * ln(rand) >= expiry.
* Probability of early recompute rises non-linearly as expiry approaches.
*/
private boolean shouldRecompute(long deltaElapsed, long expiration) {
//U factor, random between 0.0 - 1.0
double random = ThreadLocalRandom.current().nextDouble();
double gap = -deltaElapsed * BETA * Math.log(random);
return System.currentTimeMillis() + gap >= expiration;
}
...
}Stale While Revalidate
No SWR, também precisamos de metadados, como cachedAtMs, para determinar se devemos aplicar a revalidação ou não. A condição se baseia na idade do cache: se a idade for maior ou igual ao valor de refresh, a atualização é disparada em segundo plano, enquanto o dado atual continua sendo servido.
@Component("SWR")
public class StaleWhileRevalidateStrategy implements StampedePreventionService {
private static final String REFRESHING_SUFFIX = ":refreshing";
...
@Value("${app.swr.fresh-ttl-seconds:10}")
private long freshTtlSeconds;
@Override
public PreventionResult retrieve(String key, Supplier<Object> loader, Tags tags) {
var cached = cacheService.get(key, CacheEntry.class);
if (cached == null) {
var value = loader.get();
cacheService.save(key, CacheEntry.of(value));
meterRegistry.counter("cache.miss", tags).increment();
return new PreventionResult(value, false);
}
long ageMs = System.currentTimeMillis() - cached.cachedAtMs();
long freshTtlMs = Duration.ofSeconds(freshTtlSeconds).toMillis();
if (ageMs >= freshTtlMs) {
//Mechanism to ensure only one thread fire data update
boolean shouldRefresh = Boolean.TRUE.equals(
cacheService.saveIfAbsent(key + REFRESHING_SUFFIX, "1", Duration.ofSeconds(freshTtlSeconds))
);
if (shouldRefresh) {
Thread.ofVirtual().start(() -> {
var value = loader.get();
cacheService.save(key, CacheEntry.of(value));
cacheService.invalidate(key + REFRESHING_SUFFIX);
});
meterRegistry.counter("cache.revalidation", tags).increment();
}
}
meterRegistry.counter("cache.hit", tags).increment();
return new PreventionResult(cached.value(), true);
}
...
}Testes e Métricas
Os testes foram executados em ambiente local containerizado com recursos intencionalmente limitados para amplificar o efeito do cache stampede e tornar os resultados observáveis e mensuráveis:
| Componente | Configuração |
|---|---|
| Aplicação | Spring Boot 4 + Tomcat (200 threads) · 1 vCPU · 512MB RAM |
| Cache | Redis 128MB · TTL de 7 dias |
| Banco de Dados | PostgreSQL 256MB · HikariCP (pool de 10 conexões) |
| Latência simulada | pg_sleep(2s) — segura a conexão HikariCP durante a query |
| Carga | 100 RPS concentrados na hot key após invalidação explícita |
| Observabilidade | Prometheus (scrape 5s) + Grafana |
Ponto Importante: A latência de 2 segundos não representa um banco real — em produção, queries simples costumam levar 5 a 50ms. O valor foi escolhido para saturar o pool HikariCP de forma controlada e tornar o efeito visível dentro do intervalo de scrape do Prometheus.
Estratégias validadas
As estratégias implementadas se dividem em dois grupos com propósitos distintos:
Reativas – validadas sob stampede real. São as únicas que atuam durante o evento, limitando o acesso ao banco a uma única thread por vez.
| Estratégia | Mecânismo | Limitação | Consistência |
|---|---|---|---|
| Lock (Mutex) | ReentrantLock bloqueante + double-check | Proteção local — não funciona com múltiplas instâncias | Forte |
| Distributed Lock | Redisson RLock via Redis pub/sub | Proteção distribuída — overhead de rede no lock | Forte |
Proativas – mitigação preventiva. Reduzem a probabilidade de um stampede ocorrer, mas não possuem mecanismo de lock. Quando o cache é invalidado explicitamente, todas sofrem o mesmo problema do baseline.
| Estratégia | Mecânismo | Limitação | Consistência |
|---|---|---|---|
| TTL Jitter | Distribui expirações no tempo | Não protege contra invalidação explícita | Forte |
| Stale-While-Revalidate | Serve o dado stale e regenera em background | Inadequado para dados que exigem precisão imediata (saldo, estoque, preço) | Eventual |
| Probalistic Early Expiration | Recomputa o dado com base na probabilidade antes de expirar | Não protege contra invalidação explícita | Forte |
Resultados
Stampede Exposto
- ~200 threads foram diretamente ao banco simultaneamente
- O pool HikariCP (10 conexões) foi esgotado em milissegundos
- Threads excedentes entraram em fila aguardando conexão disponível
- 50 requisições com timeout (30s) — falhas visíveis ao cliente
- hikaricp_connections_active = 10 (pool saturado) durante todo o burst
Mutex
- Apenas 1 thread adquiriu o lock e executou a query no banco
- As demais threads aguardaram o lock, fizeram double-check -> cache hit -> retornaram sem tocar o DB
- 0 erros HTTP
- hikaricp_connections_active = 1 durante a fase crítica
Distributed Lock
Comportamento equivalente ao Mutex, porém o lock é coordenado via Redis pub/sub. Uma única thread executa a query; as demais bloqueiam eficientemente sem ocupar threads do Tomcat aguardando.
| Métrica | Stampede | Mutex | Distributed Lock |
|---|---|---|---|
| DB Calls | ~200 | 1 | 1 |
| Cache hit ratio | 90.00% | 99.95% | ~99.95% |
| Latência (P95) | 19.24s | 1.03s | ~1.12s |
| Latência (P99) | 30s | 1.82s | 1.84s |
| Latência Max | 30s (timeout) | 2s | 2.01s |
| HTTP Errors | 50 | 0 | 0 |
| HikariCP connections active | 10 (Saturado) | 1 | 1 |
Pontos Importantes:
1 – As estratégias proativas não foram validadas no teste de carga dado a exclusividade dos cenários.
2 – fase de stampede dura 20 segundos, mas a janela de destruição se concentra nos primeiros ~2s — o tempo que o pg_sleep segura as conexões HikariCP. Nesse intervalo, ~200 requests encontram cold cache e vão ao banco simultaneamente, saturando o pool. A partir do momento que o primeiro retorno salva o dado no cache, os 18 segundos restantes são quase 100% hits — e isso puxa o hit rate da fase inteira para 90%. O hit rate não revela o problema. As métricas que revelam são p99 = 30s, 50 timeouts e pool HikariCP saturado. Em um sistema real com latência menor no banco, a janela de destruição seria mais curta e o hit rate seria ainda mais enganoso.
Conclusão
O experimento confirma o mecanismo central do cache stampede: uma única invalidação é suficiente para saturar o pool de conexões quando não há proteção. Com o HikariCP limitado a 10 conexões e 100 RPS chegando simultaneamente, o pool foi esgotado em milissegundos, gerando filas, latência explosiva e falhas para o cliente.
O Lock (Mutex) eliminou o problema no banco de dados, mas transferiu a contenção para a fila do lock — o p99 caiu de 30s para 1.82s, refletindo o tempo de espera pelo lock, e não mais pela disponibilidade do pool.
O Distributed Lock mantém o mesmo comportamento, com a vantagem de funcionar em ambientes multi-instância.
Entre as estratégias proativas, Probabilistic Early Expiration é uma das mais recomendadas pela literatura. Ao recomputar antecipadamente de forma probabilística — com probabilidade crescendo de forma não linear conforme o TTL se aproxima da expiração — ele evita o cold cache sem servir dados stale, mantendo consistência forte. Como desvantagem, não protege contra invalidações explícitas, sendo mais adequado para cenários em que a expiração é controlada por TTL de maneira natural.
O Stale While Revalidate é a alternativa quando o domínio tolera consistência eventual. Ele oferece a menor latência possível ao nunca bloquear o cliente, mas não é adequado para dados que exigem precisão imediata, como saldos, estoques ou permissões de acesso.
O TTL Jitter é a estratégia mais simples de adotar e pode ser combinada com qualquer outra como primeira linha de defesa. Ao distribuir as expirações ao longo do tempo, reduz a probabilidade de múltiplas chaves expirarem simultaneamente.
Em sistemas críticos, a abordagem ideal é combinar as duas estratégias proativas, para reduzir a frequência de stampedes, e reativas, para garantir proteção quando eles ocorrerem.
O codigo fonte está disponível no github. Para reproduzir as estatégias, basta seguir o README.md e observar os gráficos via grafana.
Referências
https://cseweb.ucsd.edu/~avattani/papers/cache_stampede.pdf
https://www.adayinthelifeof.nl/2010/07/29/minimizing-cache-stampedes
https://engineering.fb.com/2010/09/23/uncategorized/more-details-on-today-s-outage/
Deixe um comentário