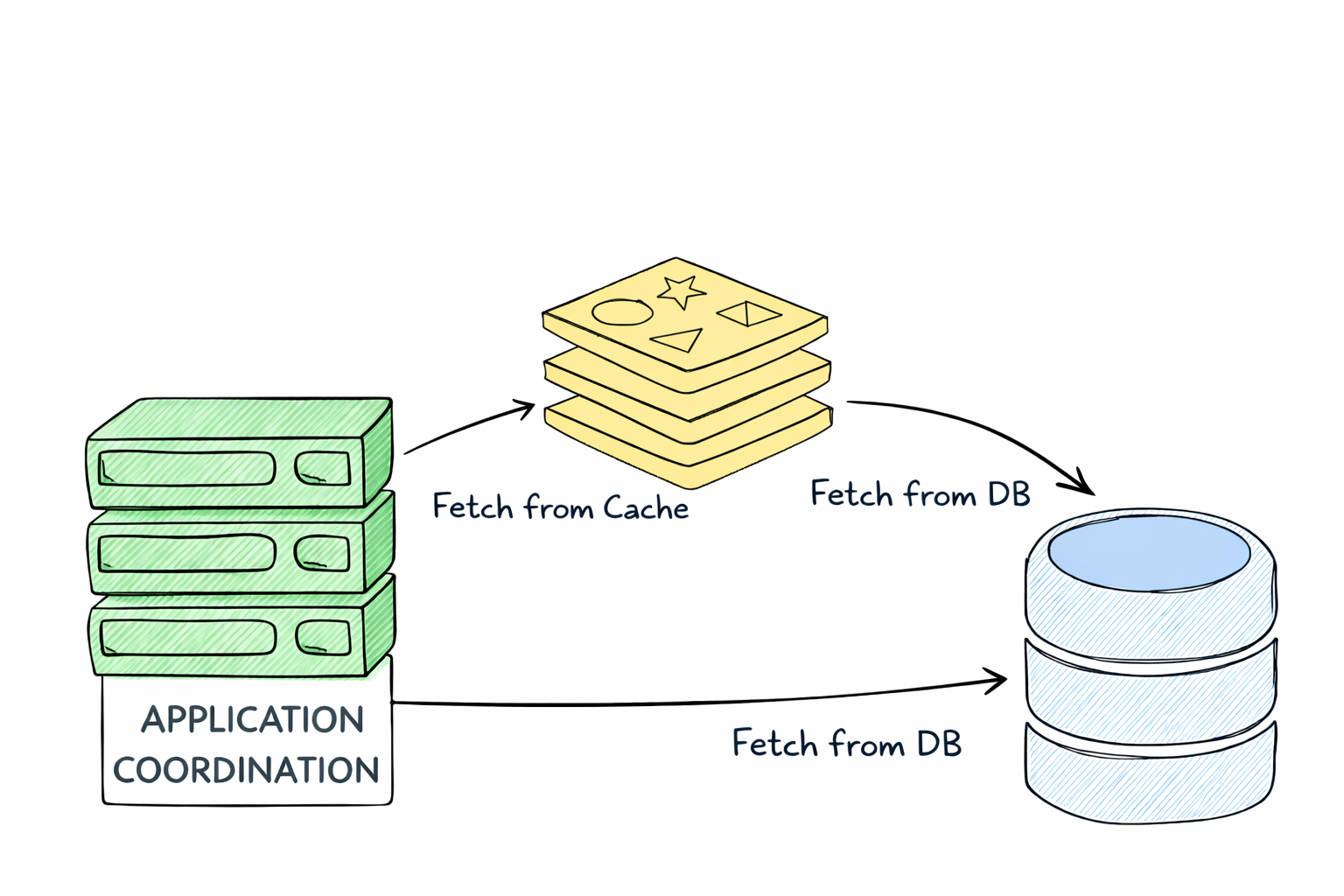
Voltando com a série Masterizando Cache em Aplicações, no post de hoje iniciamos a discussão sobre as estratégias de cache.
Uma das estratégias mais utilizadas na indústria é o padrão Cache-Aside também conhecido como Lazy Loading. Nesse modelo, a aplicação assume total responsabilidade por gerenciar o cache — decidindo quando ler, quando escrever e quando invalidar dados.
Ao utilizar um cache distribuído como o Redis, adicionamos uma camada intermediária entre a aplicação e o banco de dados. Essa camada tem como objetivo principal reduzir latência, aliviar a carga no banco e aumentar a capacidade de resposta do sistema.
Diferente de outras abordagens, o cache-aside não é automático. O cache não é preenchido previamente, nem atualizado de forma transparente. Ele é, por definição, reativo.
o dado só vai para o cache quando alguém pede por ele.
O banco de dados continua sendo a referência principal. O cache é apenas uma otimização.
Funcionamento
Fluxo de leitura
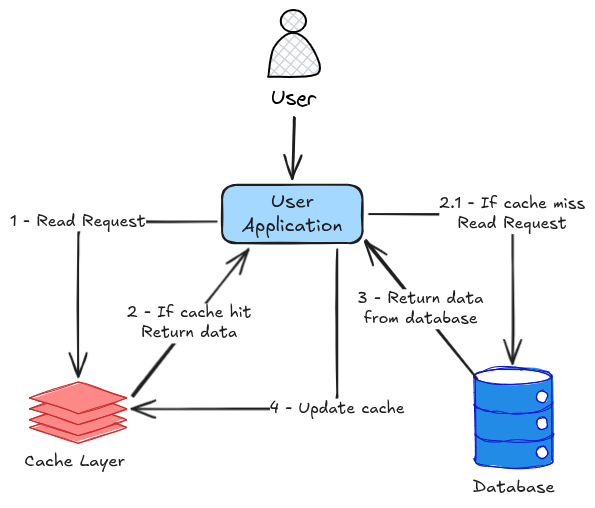
Quando a aplicação recebe uma requisição — por exemplo, buscar um usuário — ela não vai diretamente ao banco. Primeiro, ela consulta o cache.
Se o dado estiver presente cache hit, ele é retornado imediatamente. Esse é o cenário ideal: baixa latência, nenhuma carga adicional no banco e resposta rápida para o usuário.
Por outro lado, se o dado não estiver no cache cache miss, a aplicação precisa recorrer ao banco de dados. Após obter o resultado, ela armazena esse dado no cache geralmente com um TTL e então retorna a resposta.
⚠️ Concorrência e efeitos colaterais
Agora imagine um cenário mais realista.
Uma chave de cache expira exatamente no momento em que múltiplas requisições chegam simultaneamente. Todas elas vão perceber que o cache está vazio e irão consultar o banco ao mesmo tempo.
Esse fenômeno é conhecido como cache stampede e pode gerar picos de carga significativos no banco de dados. Esse tipo de problema não aparece em ambientes simples, mas é extremamente comum em sistemas de alta escala.
Fluxo de escrita
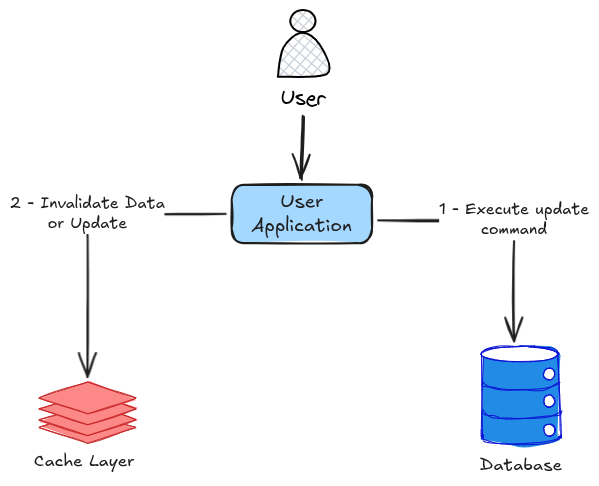
Diferente da leitura, o cache não é automaticamente atualizado. A aplicação precisa decidir o que fazer após modificar um dado no banco.
A abordagem mais comum é o padrão write + invalidate.
Nesse fluxo, a aplicação primeiro atualiza o banco de dados e, em seguida, remove a chave correspondente do cache. Isso garante que, na próxima leitura, o dado será reconstruído com o valor mais recente.
Essa estratégia é amplamente adotada porque reduz o risco de inconsistência, especialmente em sistemas distribuídos com múltiplas instâncias da aplicação.
Existe também a alternativa de atualizar o cache diretamente após a escrita write + update, mas essa abordagem exige maior controle e pode introduzir inconsistências sutis, principalmente quando há concorrência entre múltiplas instâncias.
invalidar é mais seguro do que tentar manter o cache sincronizado manualmente.
Trade-offs
O cache-aside é extremamente popular, mas não é uma solução mágica. Ele traz benefícios claros, mas também impõe desafios que precisam ser compreendidos.
👍 Vantagens
Um dos maiores atrativos desse padrão é a sua simplicidade. Ele não exige mudanças profundas na arquitetura e pode ser introduzido de forma incremental.
Outro ponto importante é a resiliência. Se o Redis falhar, o sistema continua funcionando — apenas mais lento. Isso mantém o banco como fallback seguro.
Além disso, o cache-aside escala muito bem em cenários de leitura intensa. Ao descarregar o banco, ele permite que o sistema suporte um volume muito maior de requisições.
Por fim, ele oferece controle total à aplicação. Você decide exatamente o que cachear, por quanto tempo e em quais situações.
👎 Desvantagens
A principal desvantagem é a inconsistência temporal.
Entre o momento em que um dado é atualizado no banco e o momento em que o cache é invalidado ou reconstruído, existe uma janela onde o sistema pode servir dados desatualizados.
Outro problema relevante é o já mencionado cache stampede, que pode causar picos inesperados de carga no banco.
Além disso, embora o padrão pareça simples, ele esconde uma complexidade significativa. Estratégias de invalidação, controle de concorrência e tuning de TTL são aspectos que exigem atenção cuidadosa em sistemas reais.
Também existem problemas clássicos associados ao uso de cache, como:
- cache penetration (consultas para dados inexistentes)
- cache avalanche (muitas chaves expirando ao mesmo tempo)
Esses problemas geralmente surgem apenas em escala, mas precisam ser considerados desde o início.
Quando utilizar
O cache-aside não é uma solução universal. Ele funciona muito bem em determinados cenários, mas pode ser inadequado em outros.
Ele é especialmente indicado para sistemas com alto volume de leitura e baixa frequência de escrita. Casos como catálogos, perfis de usuário e dashboards são exemplos clássicos.
Também é uma boa escolha quando o sistema pode tolerar consistência eventual. Ou seja, quando pequenas defasagens nos dados não comprometem a experiência do usuário.
Outro fator importante é a capacidade de reconstrução do dado. Se o dado pode ser facilmente obtido novamente a partir do banco, o cache-aside funciona muito bem.
Por outro lado, existem cenários onde ele deve ser evitado.
Sistemas que exigem consistência forte — como controle de saldo financeiro em tempo real — não se beneficiam desse padrão. Da mesma forma, aplicações com alta taxa de escrita tendem a invalidar o cache com frequência, reduzindo seu valor.
Implementação
Sendo bem simples, a implementação foi construída com o intuito de apresentar a otimização de um fluxo de busca de e-mails de usuários. Abordaremos aqui apenas os trechos de código relevantes; toda a implementação está disponível no GitHub
Fluxo de leitura
@Override
public UserEmail getUserEmail(UUID userId) {
var key = cacheKey(userId);
var cachedEmail = redisTemplate.opsForValue().get(key);
if (cachedEmail != null) {
meterRegistry.counter("cache.email.hit")
.increment();
return new UserEmail(cachedEmail.toString(), true);
}
var email = slowDatabaseLookup(userId);
redisTemplate.opsForValue().set(key, email, CACHE_TTL);
meterRegistry.counter("cache.email.miss")
.increment();
return new UserEmail(email, false);
}Basicamente, o trecho de código acima primeiro realiza a busca do e-mail diretamente na camada de cache. Caso o dado exista, ele é retornado imediatamente para a camada de apresentação, e a métrica cache.email.hit é incrementada.
Caso não seja encontrado, é necessário buscar o dado diretamente na base de dados. Por motivos de teste, a função slowDatabaseLookUp simula a latência do banco aplicando um Thread.sleep() aleatório. Em seguida, o dado retornado é armazenado na camada de cache, otimizando futuras requisições. Por fim, a métrica cache.email.miss é incrementada.
Fluxo de escrita
@Override
public void updateUserEmail(UUID userId, String email) {
var user = repository.findById(userId).orElseThrow(() -> new NoSuchElementException("User not found: " + userId));
user.setEmail(email);
//Using here Write + Invalidate strategy
repository.save(user);
redisTemplate.delete(cacheKey(userId));
}Aqui aplicamos a estratégia write + invalidate no fluxo de atualização, visando mitigar inconsistências de dados.
Eficiência do cache
Existem métodos para determinar se o cache implementado é eficiente ou não. Particularmente, costumo utilizar duas métricas: o cache hit ratio e a redução na latência.
Para o cálculo do cache hit ratio, incluí duas métricas — cache.email.hit e cache.email.miss — que podem ser coletadas diretamente no endpoint do actuator /user/actuator/metrics/{metricName}.
| {“availableTags”:[],”measurements”:[{“statistic”:”COUNT”,”value”:148.0}],”name”:”cache.email.hit”} | { “availableTags”: [], “measurements”: [ { “statistic”: “COUNT”, “value”: 7 } ], “name”: “cache.email.miss” } |
Aplicando os dados a formula abaixo
cache hit ratio = cache hit/(cache hit + cache miss) * 100
CHR = 148/(148+7) = 148/155*100 = 95.48%
De acordo com a Cloudflare, um bom hit ratio está entre 95% e 99%. Logo, pode-se concluir que a implementação do cache-aside cumpriu seu papel de otimização com eficiência.
Na próxima publicação, abordaremos a estratégia de cache read-through.
Deixe um comentário