À medida que evoluímos no uso de cache em sistemas distribuídos, começamos a perceber um padrão: grande parte da complexidade não está no cache em si, mas na forma como a aplicação interage com ele.
No modelo cache-aside, vimos que a aplicação precisa tomar diversas decisões:
- quando buscar no cache
- quando ir ao banco
- quando popular o cache
Esse controle dá flexibilidade, mas também aumenta a responsabilidade.
O padrão Read-Through Cache surge justamente como uma tentativa de abstrair essa complexidade.
Nesse modelo, a aplicação deixa de lidar diretamente com o banco de dados em cenários de leitura. Em vez disso, ela interage exclusivamente com o cache — como se ele fosse a única fonte de dados.
Ao utilizar um mecanismo de read-through com um sistema como o Redis, o cache passa a ter um papel mais ativo: ele não apenas armazena dados, mas também sabe como buscá-los quando necessário.
O cache deixa de ser passivo e passa a ser um participante inteligente da arquitetura.
Essa mudança, embora sutil, altera significativamente o desenho do sistema.e a aplicação e o banco de dados. Essa camada tem como objetivo principal reduzir latência, aliviar a carga no banco e aumentar a capacidade de resposta do sistema.
Funcionamento
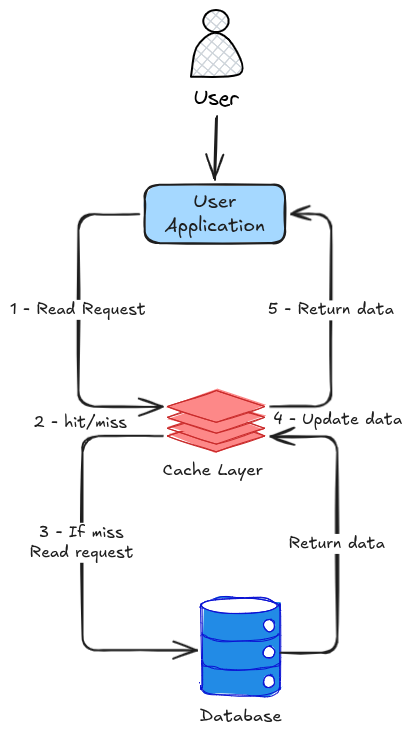
Quando a aplicação precisa de um dado, ela não se preocupa com fallback ou com o estado do cache. Ela simplesmente faz uma chamada ao cache.
Se o dado já estiver presente cache hit, ele é retornado imediatamente — comportamento idêntico ao cache-aside.
A diferença aparece no cenário de cache miss.
Ao invés da aplicação buscar o dado no banco, o próprio cache detecta a ausência e aciona um mecanismo interno — geralmente chamado de cache loader.
Esse loader é responsável por:
- consultar o banco de dados
- obter o dado atualizado
- armazenar o resultado no cache
- retornar o valor para a aplicação
Do ponto de vista da aplicação, nada disso é visível. Ela apenas pediu um dado — e recebeu.
🧠 Onde está a complexidade?
No cache-aside, a complexidade estava explícita no código da aplicação.
No read-through, essa complexidade não desaparece — ela apenas muda de lugar.
Ela passa a viver:
- no cache loader
- na infraestrutura
- na camada de abstração
Esse é um ponto fundamental para entender o padrão.
Trade-offs
👍 Vantagens
Uma das principais vantagens é a simplicidade na aplicação.
Ao remover da aplicação a responsabilidade de lidar com cache miss e fallback para o banco, o código se torna mais limpo e menos propenso a erros.
Além disso, a lógica de acesso a dados fica centralizada. Em vez de cada serviço implementar sua própria estratégia de cache, existe um único ponto responsável por isso.
Isso facilita:
- manutenção
- padronização
- evolução da arquitetura
Outro ponto positivo é a consistência de comportamento. Todas as leituras seguem o mesmo fluxo, o que reduz variações e bugs difíceis de identificar.
👎 Desvantagens
Por outro lado, essa centralização vem com um custo.
O primeiro deles é o acoplamento. O cache passa a conhecer detalhes do banco e do domínio, o que quebra um pouco a ideia de separação de responsabilidades.
Outro ponto é a complexidade operacional. Implementar e manter loaders, lidar com falhas e garantir observabilidade adequada não é trivial.
Além disso, você perde parte do controle fino que existia no cache-aside. Decisões específicas por contexto ou endpoint se tornam mais difíceis de implementar.
E, talvez o mais importante: o debug tende a ser mais complexo. Quando algo dá errado, o fluxo não está mais explícito na aplicação, e entender o problema pode exigir navegar por múltiplas camadas.
Podemos enquadrar como single-point-of-failure, caso o cache loader esteja diretamente implementado na camada de cache. Se ocorrer um outage no nó do cache, todas aplicações consumidoras ficariam sem conexão de leitura com a base principal.
Quando utilizar
O read-through não é melhor ou pior que o cache-aside — ele resolve um problema diferente.
Ele é especialmente útil em cenários onde há múltiplos pontos de leitura para os mesmos dados. Nesses casos, centralizar a lógica de cache evita duplicação e inconsistência entre serviços.
Também é uma boa escolha em times maiores, onde padronização é importante. Reduzir decisões individuais sobre cache ajuda a manter o sistema mais previsível.
Outro cenário interessante é quando o domínio é bem definido e as regras de acesso aos dados são estáveis. Isso facilita a implementação de loaders consistentes.
Por outro lado, o padrão pode ser desnecessário em sistemas simples. Nesses casos, ele pode introduzir mais complexidade do que benefício.
Também não é ideal quando há necessidade de controle fino sobre o comportamento do cache, ou quando o uso de ferramentas como o Redis é feito de forma mais direta, sem camadas adicionais.
Implementação
Comming soon com RedisGears…
Deixe um comentário